


When we talk about PHP, it’s often simplified as a “web app language”. This used to be a hindrance, as it overlooked the wider uses and potential of the language but, as we move into Cloud solutions and microservices, the need for a strong “web language” is actually starting work in PHP’s favour.
After all, as every PHP developer will tell you, the language is highly suited for web applications and server-side scripting — which sounds an awful lot like the Cloud, right? So, naturally, there’s some strong potential to pair PHP with the likes of Amazon Web Services (AWS).
I refer to AWS because I specifically had the opportunity to do just that when we were tasked with creating a new product for a client in the HR sector. Due to their specific nature and requirements, it was very quickly decided that microservices and AWS would be the most beneficial. Subsequently, PHP became a natural selection in this case — which is where my adventure began.
The Project
Once we started our project with a new customer in the HR industry, we wanted to create an architecture that would fit their needs. We defined some of the areas that must be covered, like the extensibility of the application, the possibility to divide work across different teams, the ability to cooperate with external tools, and — of course — maintainability in the context of different customer needs.
The last point is quite important, as this application is a typical multi-tenant solution (where in different users and groups need to run their own instances, unique and private to them, while still accessing a shared server or database) and all of these tenants/users seem to have slightly different requirements. Furthermore, when considering the architecture in the context of various countries it could be used in, one might conclude that, for instance, it’s crucial to be able to implement different rules for businesses working in multiple countries.
Straight away, microservices seemed to be a good choice. Currently, there’s a lot of hype around microservice architecture. However, the term itself allows for some amount of, let’s say, “Interpretational freedom”. Here, I want to explore just what microservices means for us, as well as how we implemented them in this particular situation.
Why Microservices?
Let’s start from the beginning: we know the pros & cons of this approach. We are aware, for example, that microservices allow for strong responsibility decoupling, allowing us to focus on the given part of a software and enabling the development of different parts of the application in different technologies.
There are a lot more advantages of using microservices, but we also know that “there is no such thing as a free lunch”. Microservices come with strong communication issues — all your components must still cooperate and talk to each other, even if they’re built in isolation. Of course, there are design patterns that facilitate these tasks, but this is still one of the hardest things to do when designing the architecture for microservices.
When you think of real microservice implementations and, further down the line, the deployment process, you could easily switch to the concept of Cloud services. Of course, this is an obvious solution — with the use of Cloud solutions, you could create an elastic and highly available infrastructure for your microservices. You could also use native Cloud services, such as databases, cache engines or queues. These are in fact the most often used components in basic microservice architectures.
All of this is easy to create — and remove when it’s no longer needed — and can be readily configured to be highly available to specific needs. It’s also very inexpensive, if you use it with care.
Pairing Microservices with the Cloud
With this in mind, we decided to utilise both microservices and the Cloud — it’s something that is quite an obvious choice nowadays. But what about the technology? Should we use Docker containers or virtual machines? What infrastructure-as-a-service tool should we use — the one that the Cloud provider offers (like CloudFormation in AWS) or a universal option, such as terraform? Likewise, what’s the better choice for continuous integration — Jenkins or CodeBuild? And — last but not least — what language and framework should we use?
The answers are not so simple and they most often depend on the skills you have. Yes, let’s forget about our “ideal choices”, “dreams” and so on. If you are an experienced terraform developer, you will likely never use CloudFormation — even if you think or know that the latter is better (or vice versa, no matter). The same is true for languages and frameworks — you will always use the technology that you’re familiar with.
Of course, it’s also true that some options just aren’t applicable in certain situations. We can assume that you won’t try to use PHP for multi-threaded calculations. Yeah, there are some things that some languages are better in than others — let this inform your decision.
Yet for any — even a complex — business application, PHP can be a very good choice, especially when used with very mature frameworks, such as Symfony. What is more, I can tell you that we’ve done this. Furthermore, it works perfectly and is easily manageable.
System Architecture
The question at the beginning was simple: how can we implement the solution, using a modular approach, with (possibly) distributed teams and the architecture in which we could replace one component with another one, just by using the same contract? For example, when the salary management component will have to be replaced by the external salary system, but only for a specific customer?
The solution is quite obvious: let’s use microservices and let’s decouple the responsibilities strongly. What does this mean, in reality? Each microservice is responsible for a part of the business features, with strictly defined borders of the bounded contexts we’ve defined. The application we developed is a Human Resource Management system, so there are some clear business subdomains identified:
- General identity management — this component should take care of the system authentication and authorisation;
- System management — a component used for product management and purchases processing — everything that is not customer specific;
- Publication management — the system also allows for creating and managing internal publications;
- Employment management — we can specify here the organisation structure, dependencies between employments (who’s in charge of whom) and job type management;
- Notification management — a component responsible for sending all system emails and dispatching notifications;
- Asset management — a separate module responsible for managing user assets, primarily images, movies and files.
There are of course some other business domains that we identified, all of which have their own microservice. What’s important here is that we are not using a full microservice approach because of one client’s requirement: the data provider layer must be replaceable by some other external system. This resulted in a concept of a data provider component — it acts as a clean, context independent proxy for the data infrastructure layer below.
It also means that not every microservice has its own database. Some of them do, of course, but the others are using the data provider microservice to get the information and values they need.
The overall view of the architecture looks like this:
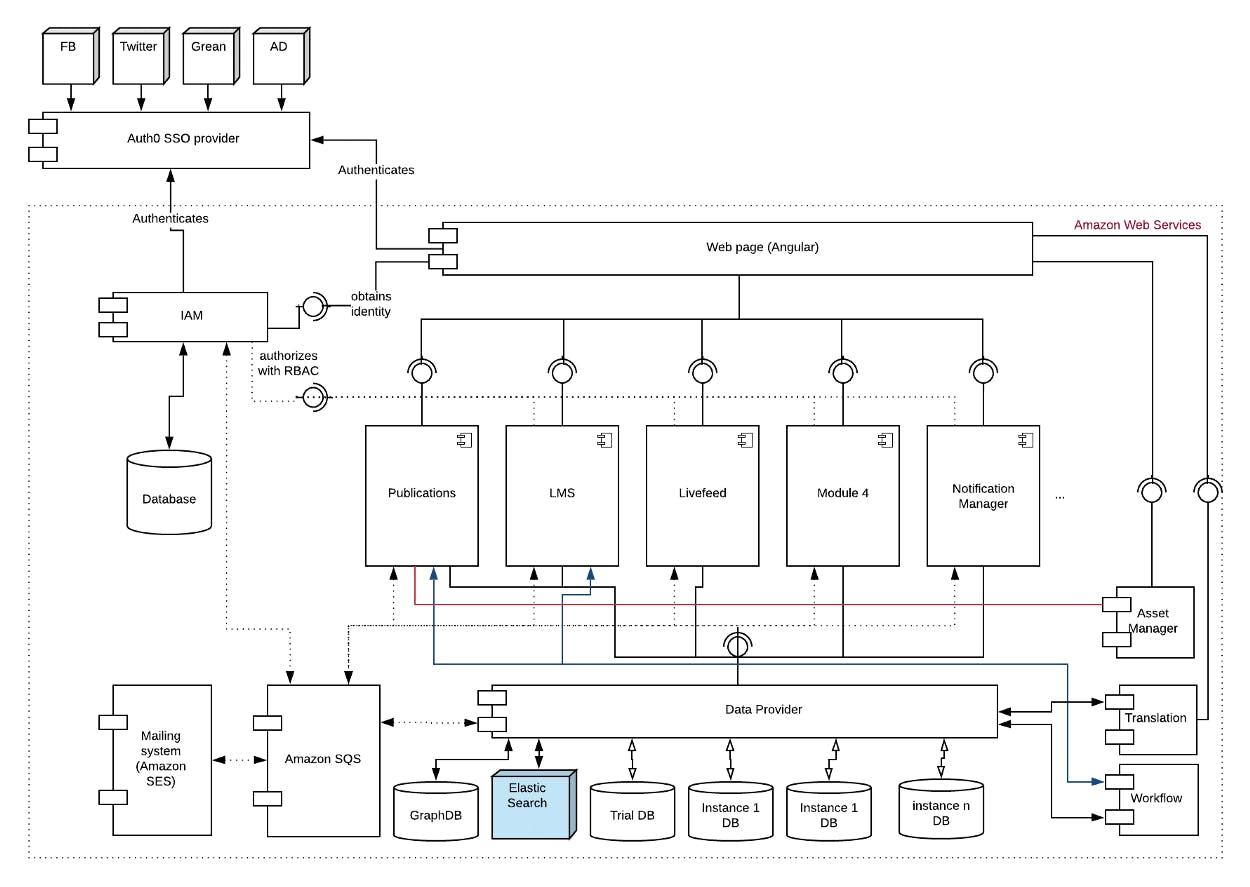
Let’s see what some of the components do and how they cooperate with each other.
Authentication Layer
This is provided by Auth0 — an external authentication provider that is compatible with OpenID. You can configure Auth0 to work with database identification (users are specific for the application only and they can create accounts inside it, just like in a traditional authentication flow), social profiles, Active Directory, SAML-compatible identity providers, and much more. Its main advantage is the ability to be seamlessly implemented using the hosted solution — the login page is on Auth0 servers, so you can just redirect users to it to enable the authentication process, which is browser-based.
Of course, Auth0 also has an Application Programming Interface (API), which enables a full backend authentication flow. We use this ability to issue our own JSON Web Token after confirming, via the Auth0 API, that the frontend authentication is correct. This allows us to manage tokens, control their lifetime and issue refresh tokens — which also gives us the ability to cut off users at any time — all without interfering with Auth0 services.
IAM
This is a microservice that plays 2 important roles. First of all, it’s a single place of authorisation for all business components. Secondly. IAM also has a role in system management — it’s a component used in the purchasing process. Of course, this is not completely in-line with the microservices approach — IAM for sure is much wider than just identity access management. It’s a place where all the purchasing activities occur and all customer instances’ configuration data is stored. This might be considered a system management service that’s common for all other business components. At the same time, it’s an authorisation endpoint for other microservices — it stores the permissions for all the system processes, using the role-based access control approach.
Modules
“Modules” are all the business components that were identified as functional subdomains. For example, this can include components connected with employment management or publication management. Every module is in fact a microservice that has a limited and well defined feature scope. For instance, the publication microservice is responsible for creating or reading publications, editing their content and preparing their structure, but it is not aware of any employment being managed inside other microservices. What does connect them, however, is the fact that both use the data provider microservice to fetch the necessary data.
Data Provider
Speaking of which, this is actually a wrapper deployed over the data infrastructure layer. It knows which data source needs to be used. Additionally, it uses the multi-tenant approach with separated databases, so every customer (tenant) has its own database and the data provider decides which database to use (or maybe the trial database should be connected). It receives connections and requests from the business modules and returns the necessary data, which can be further processed by the respective business module and returned to the frontend — or any other API client.
Notification Manager
This component is responsible for sending all system emails, but it also returns notifications to the frontend application. It’s a separate microservice and, thus, the notification logic is separated from the business logic, and it is treated as a supporting subdomain, not the business one.
… And the Rest.
There are also some other supporting microservices, such as the asset manager which manages all system assets (ie. images, movies and files) or the translation microservice which, as the name implies, manages all translations. The web page itself is also a frontend Angular web application, which calls all the business microservices, as well as authorisation and system management components.
Putting It Together
All the business components are developed using PHP 7.1 and Symfony 3.4. Depending on the component, various libraries are utilised across these microservices — it is important to consider that every microservice is, in fact, a small, separate Symfony application.
The communication between microservices is provided using 2 methods:
- Direct requests — used, for example, when a business module is calling the IAM to authorise the user action.
- A decoupled, queue-based approach — this is used when a user is making a purchase, which is then stored in a queue and asynchronously processed by the system, for instance.
Multi-Tenant System
The system itself is a typical multi-tenant application. It’s designed to be a web service for multiple end-customers. Therefore, its architecture is focused on the ease of change management, which becomes more challenging when factoring in the usage of microservices.
One of the most difficult parts of multi-tenant system is database management. Here are a couple of approaches that we used:
First of all, there is a single management database used in the IAM module. This database stores all the information about tenants and their permissions. There are some tables within that store information belonging to the given tenant and, in these cases, we use an additional column to play the role of discriminator — pointing to a given instance (tenant).
There is a single database that plays the role of a “trial” storage for customers in trial mode. Every table has a discriminator column and stores relevant business data (such as employments or publications).
- In cases where a customer is “promoted” to a paying tenant, a separate database for him or her is created. This database stores specific data that’s only for the given tenant. However, while this particular approach is more secure by design, it also comes with a lot of management hassle, as we have to keep all the tenants’ databases inline, which can involve extra tasks. For example, we may have to run migrations on all of them in cases where the schema has been changed.
- The system is also using a graph database — OrientDB, in our case. We use it to store non-predefined relations between objects, such as who’s in charge of whom or what relations are between employments or employees. This database is a single instance and it stores information regarding all tenants in one graph. This results in problems with data separation — we solved this by only storing relation types and object GUIDs (globally unique identifiers). Consequently, no business data is stored here. As for the relations, these are fetched from graph DB, while the rest of the data is fetched from the Relational Database Management System (RDBMS).
The above design allows for data separation and — at the same time — minimises management problems. Of course, managing multiple databases might seem challenging at first, but we’re using automatic data source selection in the data provider component, so it’s not a problem at all!
A Few Words about Cloud Architecture and the Deployment Process
We had a strong battle regarding the repository structure. Do we need a separate repository (multirepo) for each microservice? Perhaps a monorepo strategy is a better option? Both approaches have their pros & cons, and for some types of applications, monorepo is certainly a better choice — mainly for its simplicity of management and ease of deployment.
Usually, you deploy the whole application, not one module after another, right? Then, in such circumstances, separating the application into multiple repositories makes no sense. This is a strong argument in monorepo’s favour.
On the other hand, if you have independent, properly separated microservices, developed within strictly defined & bounded contexts, then you might think of a scenario where every microservice can be deployed independently. What’s more, every component could be developed by another, separate team.
If this is the case, then the multirepo approach is much more appropriate. However, you still have to be careful — what if you deploy new microservice A, but it is using version 2.1 of microservice B, which is currently in version 2.0? You’ll quickly find that microservice A will not work properly — you must be prepared for such scenarios.
Taking these difficulties into consideration, we decided to use a multirepo approach. It’s difficult to manage but ultimately very flexible. We can delegate the development of a given microservice to another, completely independent team without any problems. Potentially conflicting deployment scenarios are handled through a strict release process and, each time, the order of deployed components must be carefully planned. What is more, our components must always be backward compatible, at least for the previously released version of the application. Thus, we can avoid errors if, for some reason, the order of deployment is not kept accurate.
Every environment we have on AWS has its own Virtual Private Cloud, complete with separate settings, and the native Cloud services have been separately setup for all environments.
This deployment process had 2 key stages:
- The infrastructure deployment is achieved using terraform. This gives us the possibility to manage the whole infrastructure in code and simplifies any changes in the services used. For instance, if we want to run a new queue on Amazon Simple Queue Service (SQS), it’s possible to add new resources to the terraform code and apply the change(s) this way.
- Application deployment is performed using Jenkins and CodeDeploy/CodePipeline. The former is used in preparing build artifacts, as well as using parameters within AWS Parameter Store for security reasons. CodeDeploy, on the other hand, is used to deploy the code to AWS instances.
CodeDeploy, used with CodePipeline, is a flexible and powerful solution that allows for the quick setup of rolling, or blue-green, deployment inside the AWS infrastructure. The CodeDeploy package can consist of both pre-installed or post-install hooks, enabling you to inject some bash scripts to bootstrap anything you need on the server (for instance, if you have to run migrations). Furthermore, CodeDeploy, by default, supports in-place deployment with a one-at-a-time strategy (a kind of rolling deployment), which allows for zero downtime.
Summary
At this point, you may very well be thinking — “is this really all written in PHP?”. The answer is — yes, it’s PHP. With Symfony, of course. The architecture for our application is very complex, because the HR domain is complex. Using PHP with Symfony is a good answer for this kind of challenge, because:
- It’s concise
- It’s modern
- It’s modular
- It’s supported by many libraries
- It’s easily testable,
- It supports good code quality
- It makes containerisation both easy and possible
With PHP and Symfony — all of these benefits are available. But, you know what? Microservices afford us one more benefit that, while not used here, is nonetheless important going forward… every component might be built using another language, but this really doesn’t matter. As long as we use compatible contracts, the sky’s the limit!
The project is still in its early phase — it’s constantly growing, we’re adding new features and that sometimes results in the need to create new microservices. Its decoupled architecture is already paying off — every time a new module is added, we can design it as a separate microservice and this approach is also very convenient in terms of the business: release phases might be much faster, as we can easily develop new MVPs (Minimum Viable Products) without caring too much about the fact that the whole application is quite large and heavy now.
Symfony seemed to be a very good choice from the very the beginning. Well, it is still the best option if a given microservice is not a small component. However, one can think of a lighter framework, such as Slim, if a small feature microservice has to be created — this reduces the processing time, thus limiting the physical resources needed. Yet I still believe Symfony 4 could also be a perfect choice for that — and such an approach would also simplify the knowledge sharing among the team members.
Last but not least — this is still a microservices architecture: as stated before, every component might be developed in any technology, so you don’t have to just stick to PHP, of course! However, I hope this project has shown why PHP shouldn’t be so readily overlooked — in the right conditions, it can make your next project much more manageable!
Business Perspective
If you’re looking to create a multitenant application that thrives in the Cloud, PHP and microservices can offer a flexible solution that keeps individual functions separate, but well integrated and connected. The end result is a smooth delivery process that enables continued improvement on a rapid scale.